Your Paper Title Here
Abstract {-}
State the problem, the methods, the solution, the results. This document is an example of how to use pandoc/markdown and NOT necessarily a template for your actual paper contents. See the rubric for paper guidelines!
Introduction
Notice the Introduction is a SECTION. Sections can have SUBSECTIONS (seen later)
Open with the broad problem area and narrow toward your specific research question. Why should the reader care? Ground the motivation in real-world impact or a gap in the literature.
Discuss existing solutions and their shortcomings. For example, Smith et al. demonstrated that convolutional approaches plateau at roughly 87% accuracy on this task [@smith2024], while the transformer-based method of Jones and Lee [@jones2025] improved recall but at significant computational cost.
Summarize what you accomplished: “In this paper we present [X], a [brief description]. Our system achieves [key metric] on [dataset/benchmark], representing a [Y]% improvement over [baseline]. We additionally contribute [secondary contribution, e.g., a curated dataset, an open-source tool, a novel evaluation protocol].”
The remainder of this paper is organized as follows. Section 2 details the procedure and experimental design. Section 3 presents results. Section 4 offers conclusions and future work.
Procedure
Another example of a SECTION
Software and Environment
You may have SUBSECTIONS. Not required but sometimes helpful.
All source code is available at https://github.com/yourusername/your-repo.
| Component | Detail |
|---|---|
| Language | Python 3.12 |
| ML Framework | PyTorch 2.3 |
| Key Libraries | scikit-learn 1.5, pandas 2.2 |
| Hardware | NVIDIA RTX 4070, 12 GB VRAM |
| Training Time | ~4 hours per full run |
Data
Describe the dataset source, size, and how you obtained it. Provide download links or DOIs. Explain preprocessing steps (cleaning, tokenization, normalization, augmentation, train/validation/test splits) in enough detail for replication.
The dataset was obtained from the UCI Machine Learning Repository1.
Algorithm / Approach
Describe your method at a level of detail sufficient for replication. Use pseudocode where it adds clarity:
Algorithm: DESCRIPTIVE-NAME
Input: X (feature matrix, n × d), y (labels, n × 1)
Output: trained model M
1. Split X, y into train/val/test (80/10/10)
2. For each epoch e = 1 … E:
a. Compute forward pass: ŷ = M(X_train)
b. Compute loss: L = CrossEntropy(ŷ, y_train)
c. Backpropagate and update weights
d. If val_loss has not improved in P epochs: early stop
3. Return M
Experimental Design
Explain how you evaluated your system: what baselines you compared against, how many runs you averaged over, what hyperparameter search you performed, and what metrics you chose and why.
Results
Quantitative Results
Summarize performance in a table. Reference it in your prose using the label (see below).
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Baseline (SVM) | 0.872 | 0.861 | 0.880 | 0.870 |
| Our Method | 0.942 | 0.938 | 0.947 | 0.942 |
: Comparison of classification performance on the test set. {#tbl:results}
As shown in [@tbl:results], our method outperforms the SVM baseline by 7.0 percentage points in accuracy.
Figures and Visualizations
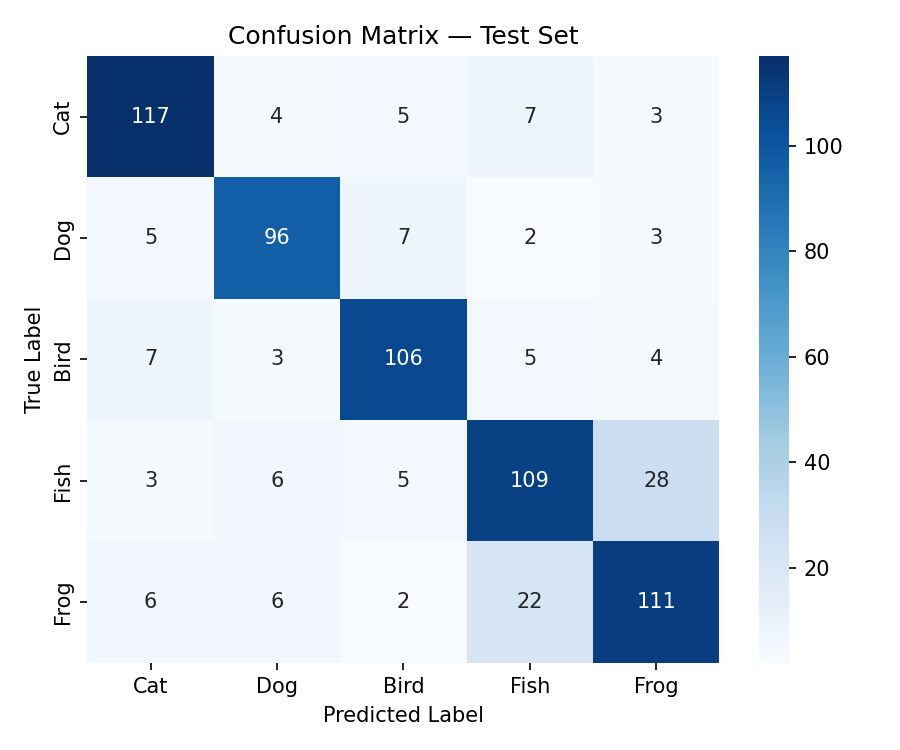 {#fig:confusion width=70%}
{#fig:confusion width=70%}
[@fig:confusion] shows that most misclassifications occur between classes 3 and 5, which share visual similarity.
Training Curves
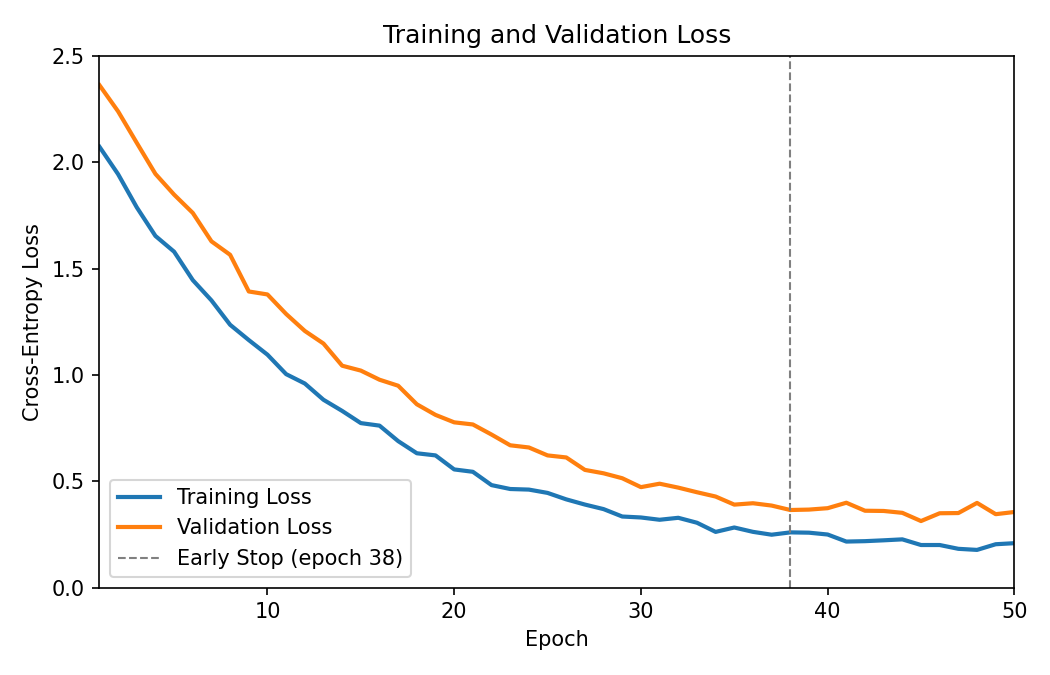 {#fig:loss width=65%}
{#fig:loss width=65%}
The training dynamics in [@fig:loss] confirm that the model converges without significant overfitting.
Final Product
Include screenshots or photos of your deliverable (app, website, model interface, hardware setup, etc.).
 {#fig:app width=80%}
{#fig:app width=80%}
Conclusions
A bit of a summary of your results, but also should look forward. What’s the TL;DR? What did you accomplish? What could be next steps for you or someone else in this area?
References {-}
::: {#refs} :::
-
https://archive.ics.uci.edu/ml/datasets/Your+Dataset — accessed April 2026. ↩